Background
In recent years, Ford adopts a more service-oriented business model, lots of data is created and being used in user research. In order to create value from this data, Research and Advanced Engineering (R&A) teams in Ford Aachen are now adapting Data-enabled design approaches in their projects and being open minded to cooperate with academic institutes.
In the first contact with them, I noticed that the cooperation project that involved two teams did not have a systematic information exchange process. As a design researcher, I thus aimed to improve the information flow between the researchers and data scientists.
stakeholders
The case I investigated is a cooperation project mainly conducted by the researchers from the craftsman vehicle team, and supported by the data scientist from the Global Data Insight and Analytics who helps them use the sensor and track the data.

Researchers (R&A)
from the Research and Advanced Engineering (R&A) Craftsman Vehicle team
.mainly conduct the project
.analyze customer behavior
.understands the project details

Data scientists (GDI&A)
from the Global Data Insight and Analytics (GDI&A)
.support R&A
.more experienced in data analysis & visualization
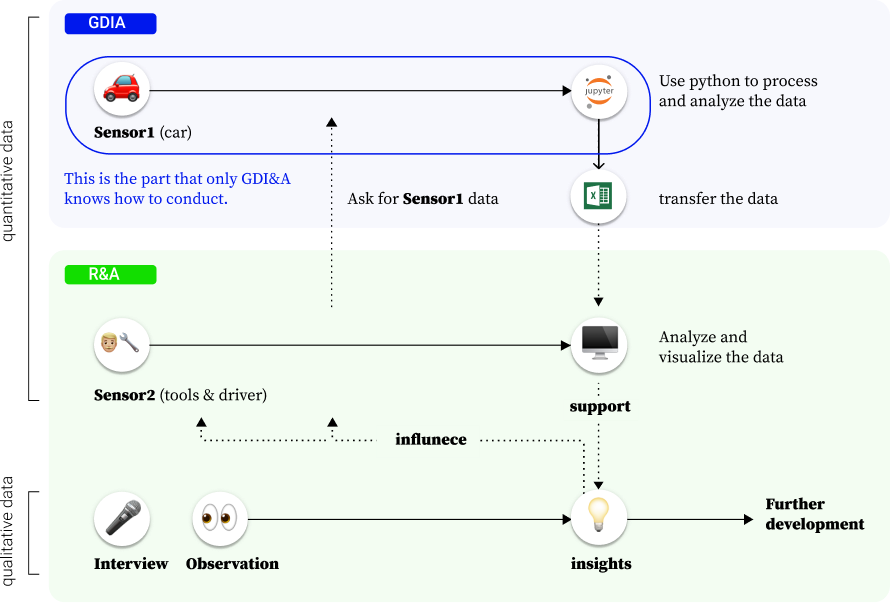
current information flow
Two kinds of data are utilized in the project. For qualitative data, observation and interviews are used to understand the craftsmen community. The insights help R&A to make decisions in the development, and influence how to collect the data in the future. However, the information and insights are not shared to GDI&A.
On the other hand, quantitative data collection is where R&A needs GDI&A to help constantly.
(1) Since only GDI&A has the technique and knowledge to access and process the data,
(2) and the language to analyze the data is different between two teams,
so when data is needed from R&A, GDI&A will access the raw data, process it, and lastly transfer it to the file that R&A can use and deliver it to R&A.
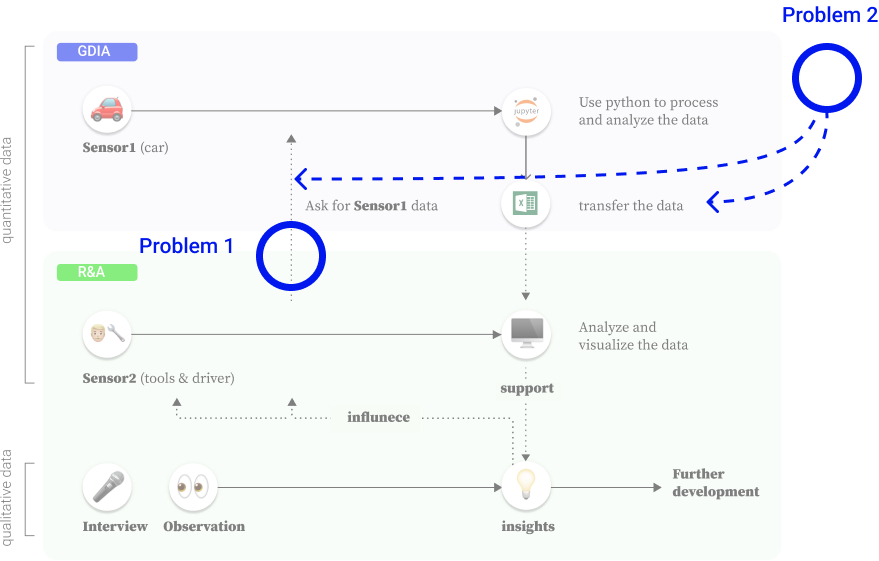
Problem definition
The parts GDI&A and R&A want to enhance from the information flow are different. GDI&A is asking for more contextualized content (insights from qualitative data) while R&A is keen to gain more support of the technical aspects or gaining inspiration from GDI&A’s previous cases.
.png)
Solution
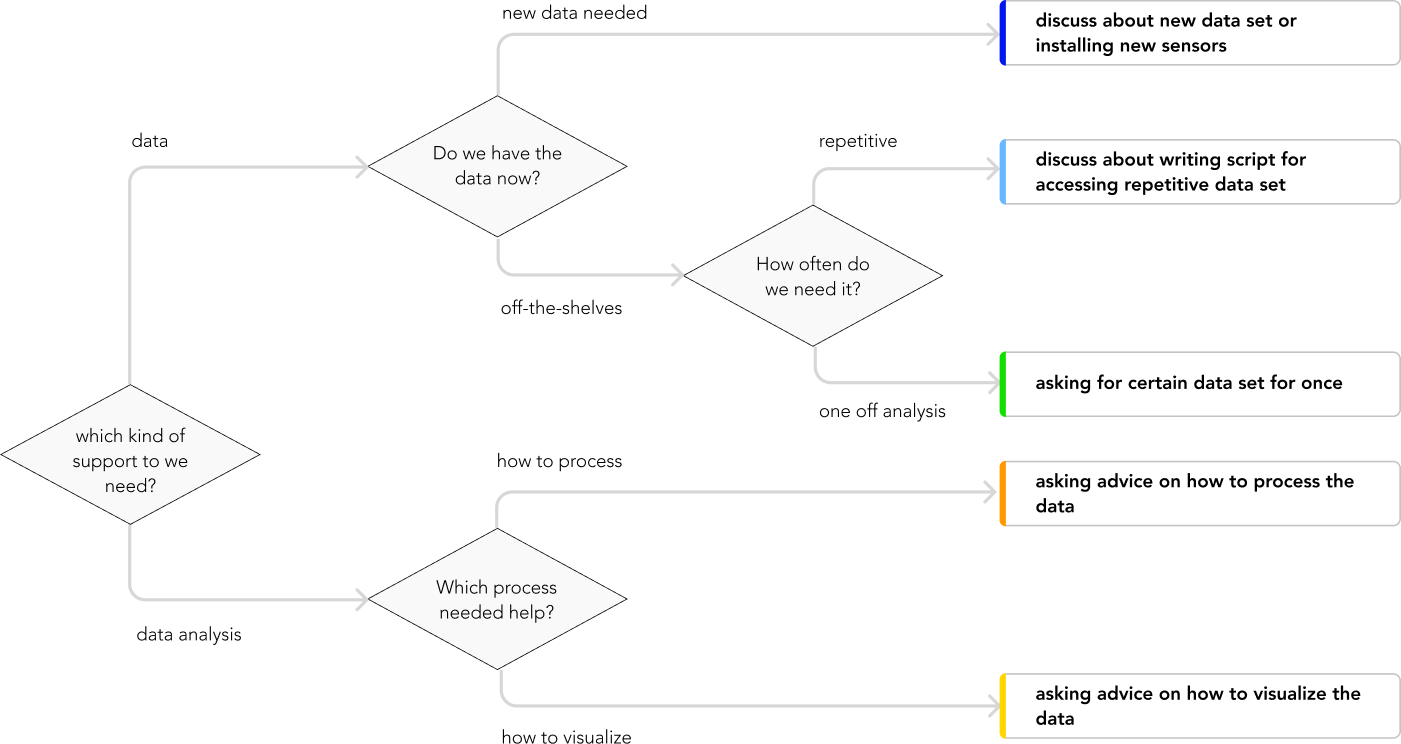
defining the classification of the request types
This classification covers all the requests that are often dropped in their collaboration. This helps the requesters (researchers) to clarify their problem, and also helps the data scientist understand and evaluate the situation faster. Besides, it is easy and cost-effective to implement. During the evaluation, this decision tree received high compliments from all the participants, who believe they can adapt this in their communication immediately.
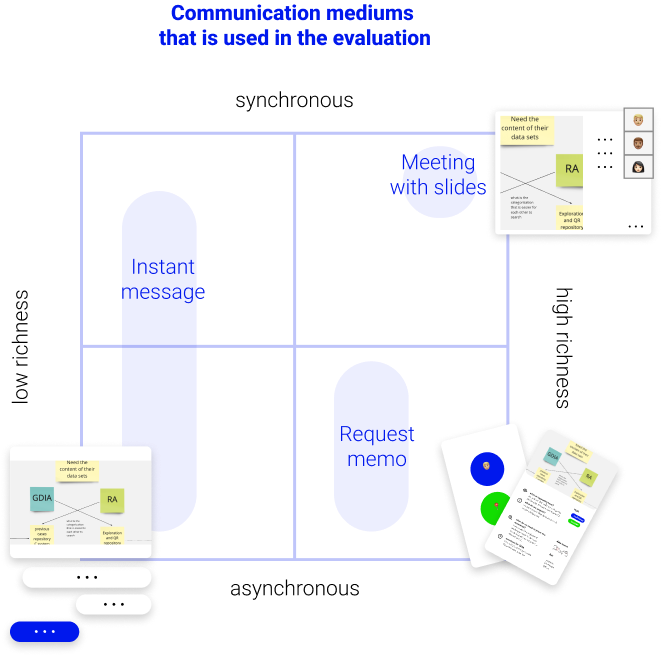
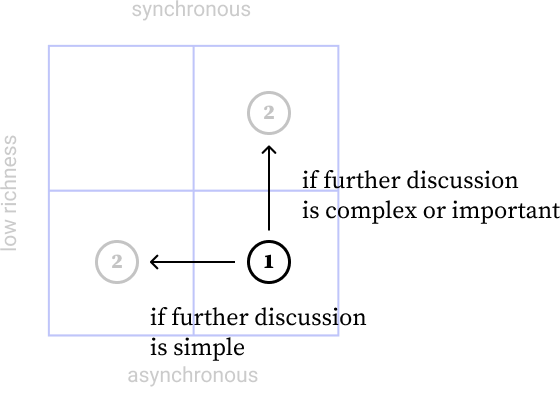
finding suitable mediums for communication
Mediums’ capability is influenced by their richness and synchronicity (real time or not). I decided to analyze the mediums by their richness and synchronicity and see which mediums suit in which scenarios.
After the evaluation of mediums, I noticed that for the collaboration, it is important to have background knowledge first before real-time communication (like meeting and instant messaging). Memo is a perfect medium to start the whole conversation, since (1) it is capable to carry the background knowledge, (2) it can provide a foundation for further real-time communication, (3) it can be documented (which can become the data in a repository that solves problem 2).
features that help the memo look clear and structured
Since the memo is a better medium to start the request, I designed a format of a memo card that consists of several features that help the requesters form their request, so it will be easier for data scientists to get the point of the requests and come up with a suitable collaboration strategy.
.png)
guideline
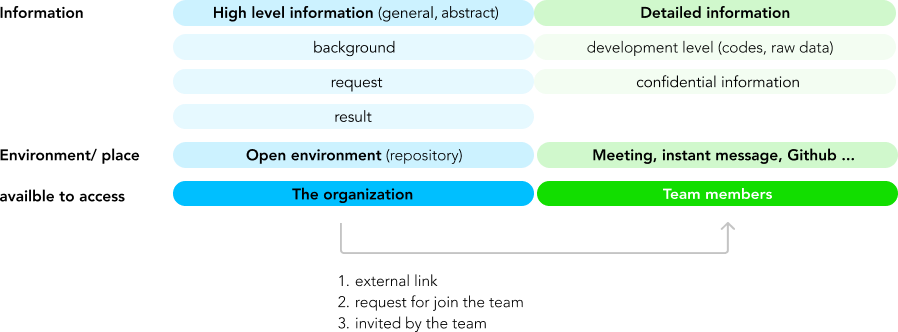
The level of sharing the details of information depends on how close the people are related to the project (Austin Govella, 2019), therefore, even though we need to document the information for further usage, we should make sure only high level information should remain on the public area.
This structure acts as a guideline to manage the knowledge in the collaboration between data scientists and the requesters.
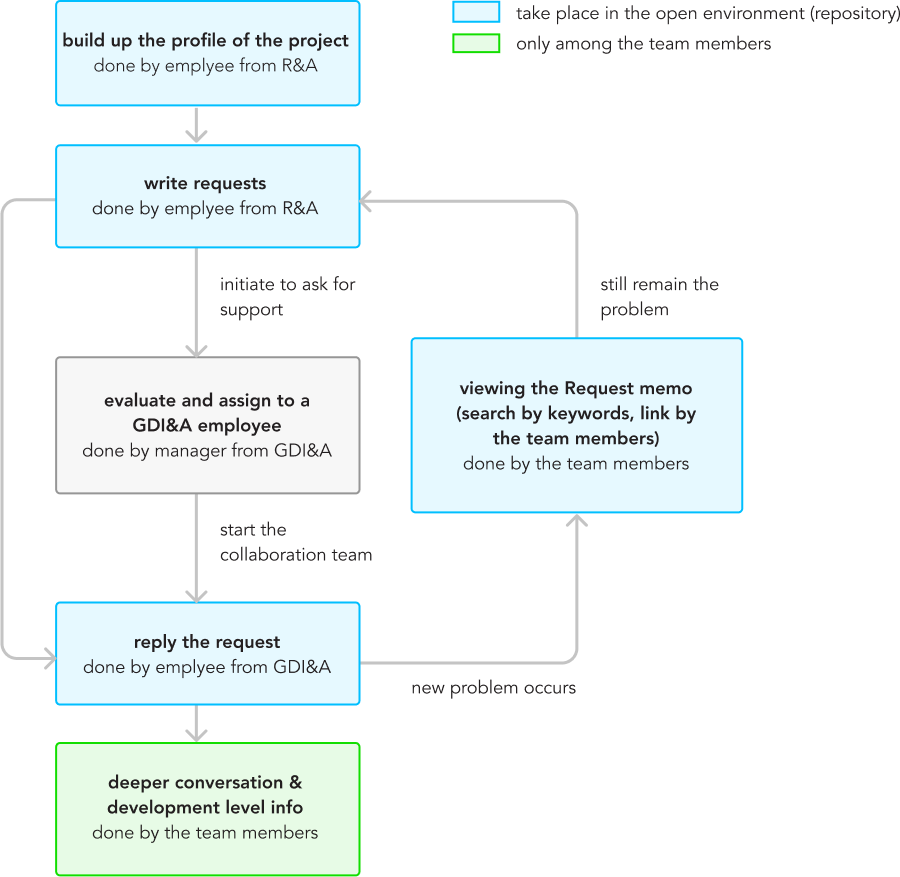
(1) Profile of the project built up in an asynchronous collaboration environment (repository).
(2) Requests will be delivered under the page of the project profile (memo).
(3) With the information on the project profile and the request, the manager of the data scientist team can decide which colleagues and strategies are the best fit for the requester. It will be the starting point of the information flow in each collaboration between data scientists and the requesters.
(4) When the collaboration starts, team members can decide on further communication based on the complexity and importance of the requests.
(5) Once the requesters have new problems, they can check on other cases of repetitive/similar requests. If requesters still have the problem, then a new request will be delivered under the project profile.
Result
The primary contributions of this project are (1) finding out the missing information in the collaboration, (2) proposing a guideline for information exchange in the collaboration between R&A and GDI&A, (3) and providing classification for them to identify the request in the collaboration.
The research shows that addressing a request with its context is better to start through asynchronous communication. Therefore, the guideline suggests building up the project profile and addressing the request in the open environment of the organization first. It allows data scientists to come up with suitable collaboration strategies and is able to equip basic knowledge for further communication.
The classification for the requests helps the researchers clarify their questions and it helps both teams (researchers and data scientists) be on the same page for the situation. The stakeholders found the classification very helpful and very cost-effective to implement.

.png)

